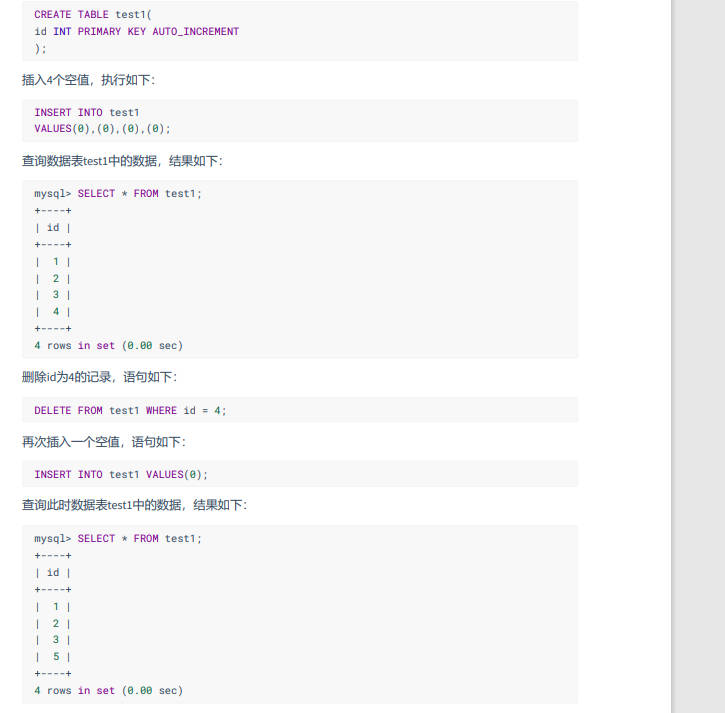
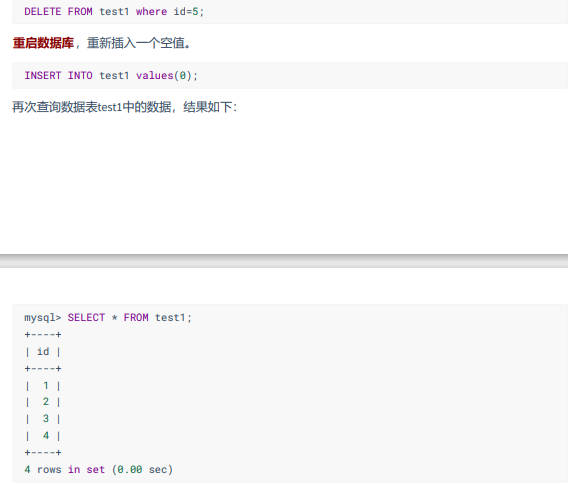
系统变量分为全局系统变量(需要添加 global 关键字)以及会话系统变量(需要添加 session 关键字),有时也把全局系统变量简称为全局变量,有时也把会话系统变量称为local变量。如果不写,默认会话级别。静态变量(在 MySQL 服务实例运行期间它们的值不能使用 set 动态修改)属于特殊的全局系统变量。
1 2 3 4 5 6 7
#查看所有全局变量 SHOW GLOBAL VARIABLES; #查看所有会话变量 SHOW SESSION VARIABLES; 或 SHOW VARIABLES;
DELIMITER // CREATE PROCEDURE update_salary_by_eid1(IN emp_id INT) SELECT salary INTO emp_salary FROM employees WHERE employee_id = emp_id; SELECT DATEDIFF(CURDATE(),hire_date)/365 INTO hire_year FROM employees WHERE employee_id = emp_id; IF emp_salary < 8000 AND hire_year > 5 THEN UPDATE employees SET salary = salary + 500 WHERE employee_id = emp_id; END IF; END // DELIMITER ;
分支结构之 CASE
1 2 3 4 5 6 7
#情况一:类似于switch CASE 表达式 WHEN 值1 THEN 结果1或语句1(如果是语句,需要加分号) WHEN 值2 THEN 结果2或语句2(如果是语句,需要加分号) ... ELSE 结果n或语句n(如果是语句,需要加分号) END [case](如果是放在begin end中需要加上case,如果放在select后面不需要)
DELIMITER // BEGIN DECLARE emp_sal DOUBLE; DECLARE bonus DECIMAL(3,2); SELECT salary INTO emp_sal FROM employees WHERE employee_id = emp_id; SELECT commission_pct INTO bonus FROM employees WHERE employee_id = emp_id; CASE WHEN emp_sal<9000 THEN UPDATE employees SET salary=9000 WHERE employee_id = emp_id; WHEN emp_sal<10000 AND bonus IS NULL THEN UPDATE employees SET commission_pct=0.01 WHERE employee_id = emp_id; ELSE UPDATE employees SET salary=salary+100 WHERE employee_id = emp_id; END CASE; END // DELIMITER ;
循环结构之LOOP
使用LOOP语句进行循环操作,id值小于10时将重复执行循环过程。
1 2 3 4 5 6 7
DECLARE id INT DEFAULT 0; add_loop:LOOP SET id = id +1; IF id >= 10 THEN LEAVE add_loop; END IF; END LOOP add_loop;
DELIMITER // CREATE PROCEDURE update_salary_while(OUT num INT) BEGIN DECLARE avg_sal DOUBLE ; DECLARE while_count INT DEFAULT 0; SELECT AVG(salary) INTO avg_sal FROM employees; WHILE avg_sal > 5000 DO UPDATE employees SET salary = salary * 0.9; SET while_count = while_count + 1; SELECT AVG(salary) INTO avg_sal FROM employees; END WHILE; SET num = while_count; END // DELIMITER ;
REPEAT语句创建一个带条件判断的循环过程。与WHILE循环不同的是,REPEAT 循环首先会执行一次循环,然后在 UNTIL 中进行表达式的判断,如果满足条件就退出,即 END REPEAT;如果条件不满足,则会就继续执行循环,直到满足退出条件为止。
1 2 3 4 5 6 7 8 9 10 11
DELIMITER // CREATE PROCEDURE test_repeat() BEGIN DECLARE i INT DEFAULT 0; REPEAT SET i = i + 1; UNTIL i >= 10 END REPEAT; SELECT i; END // DELIMITER ;
DELIMITER // CREATE TRIGGER before_insert BEFORE INSERT ON test_trigger FOR EACH ROW BEGIN INSERT INTO test_trigger_log (t_log) VALUES('before_insert'); END // DELIMITER ;
查看、删除触发器
1 2 3 4 5
SHOW TRIGGERS\G SHOW CREATE TRIGGER 触发器名 SELECT * FROM information_schema.TRIGGERS; DROP TRIGGER IF EXISTS 触发器名称;