java背诵笔记
1,计算机网络部分
基本概念
网络地址:网络地址(Network address)由ip和子网掩码按位与得出,只有网络地址相同的ip才在同一子网内
网络地址是子网中最小的地址
计算方式:网络地址 = IP & 子网掩码
广播地址:广播地址(Broadcast Address)是专门用于同时向网络中所有工作站进行发送的一个地址
广播地址是该子网主机地址全1的地址,即子网中最大的地址
计算方式:广播地址 = (~子网掩码) | 网络地址
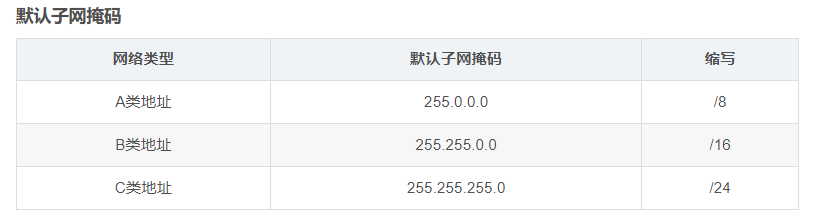
子网掩码
子网掩码 (Subnet mask)是一个32位的2进制数 ,它必须结合IP地址一起使用。
子网掩码只有一个作用,就是将某个IP地址划分成“网络地址”和“主机地址”两部分。
缩写
有时候我们会看到192.168.1.123/24这样的表示方法,其中/24就是子网掩码255.255.255.0的缩写
计算方式:二进制子网掩码中1的个数
子网容量计算
子网数
根据子网掩码可划分的最大子网数
计算方式:子网数 = 2^(实际子网掩码缩写 - 相应网络类型默认子网掩码缩写)
最大主机数
计算方式:最大主机数 = 2^(主机地址的位数)
可用主机数
计算方式:可用主机数 = 最大主机数 - 2
因为一个子网中主机号全为0的是网络地址,全为1的是广播地址,所以要 -2
1,Q:cookie,session与token的区别
A: Cookies是由服务器产生的,当浏览器第一次访问服务端为标记用户所设置独特的身份标识数据。格式为key=value,根据cookie中的值识别用户身份并传值
Session机制是一种服务端的机制 ,服务器使用一种类似散列表的结构来保存信息。server 会为用户生成一个 session,为其分配唯一的 sessionId,通过 cookie 传给浏览器。
区别:
cookie 和session的区别
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗
考虑到安全应当使用session。
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能
考虑到减轻服务器性能方面,应当使用cookie。
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
Token是在服务端将用户信息经过Base64Url编码过后传给在客户端,每次用户请求的时候都会带上这一段信息,因此服务端拿到此信息进行解密后就知道此用户是谁了,这个方法叫做JWT(JSON Web Token)。 Token类似一个令牌,无状态的,服务端所需的信息被Base64编码后放到Token中,服务器可以直接解码出其中的数据。
Token相比较于Session的优点在于,当后端系统有多台时,由于是客户端访问时直接带着数据,因此无需做共享数据的操作。
2,Q:网络的七层架构,tcp/ip在那一层
A: 计算机网络常见网络结构
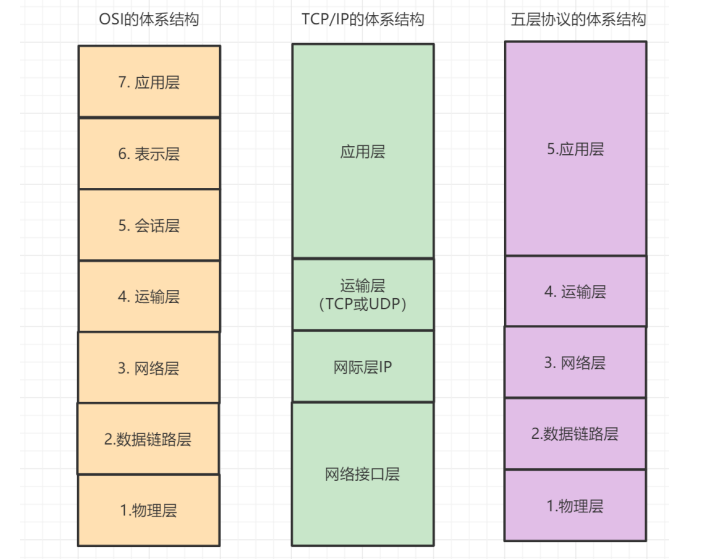
其中传输层:定义了一些传输数据的协议和端口号(WWW 端口 80 等),如:TCP(传输控制协议,传输效率低,可靠性强,用于传输可靠性要求高,数据量大的数据),UDP(用户数据报协议,与 TCP 特性恰恰相反,用于传输可靠性要求不高,数据量小的数据,如 QQ 聊天数据就是通过这种方式传输的)。 主要是将从下层接收的数据进行分段进行传输,到达目的地址后在进行重组。常常把这一层数据叫做段。
Q: TCP与UDP的区别
A:
1) TCP是面向连接的,可靠性高;UDP是基于非连接的,可靠性低
2) 由于TCP是连接的通信,需要有三次握手、重新确认等连接过程,会有延时,实时性差,同时过程复杂,也使其易于攻击;UDP没有建立连接的过程,因而实时性较强,也稍安全
3) 在传输相同大小的数据时,TCP首部开销20字节;UDP首部开销8字节,TCP报头比UDP复杂,故实际包含的用户数据较少。TCP在IP协议的基础上添加了序号机制、确认机制、超时重传机制等,保证了传输的可靠性,不会出现丢包或乱序,而UDP有丢包,故TCP开销大,UDP开销较小
4) 每条TCP连接只能时点到点的;UDP支持一对一、一对多、多对一、多对多的交互通信
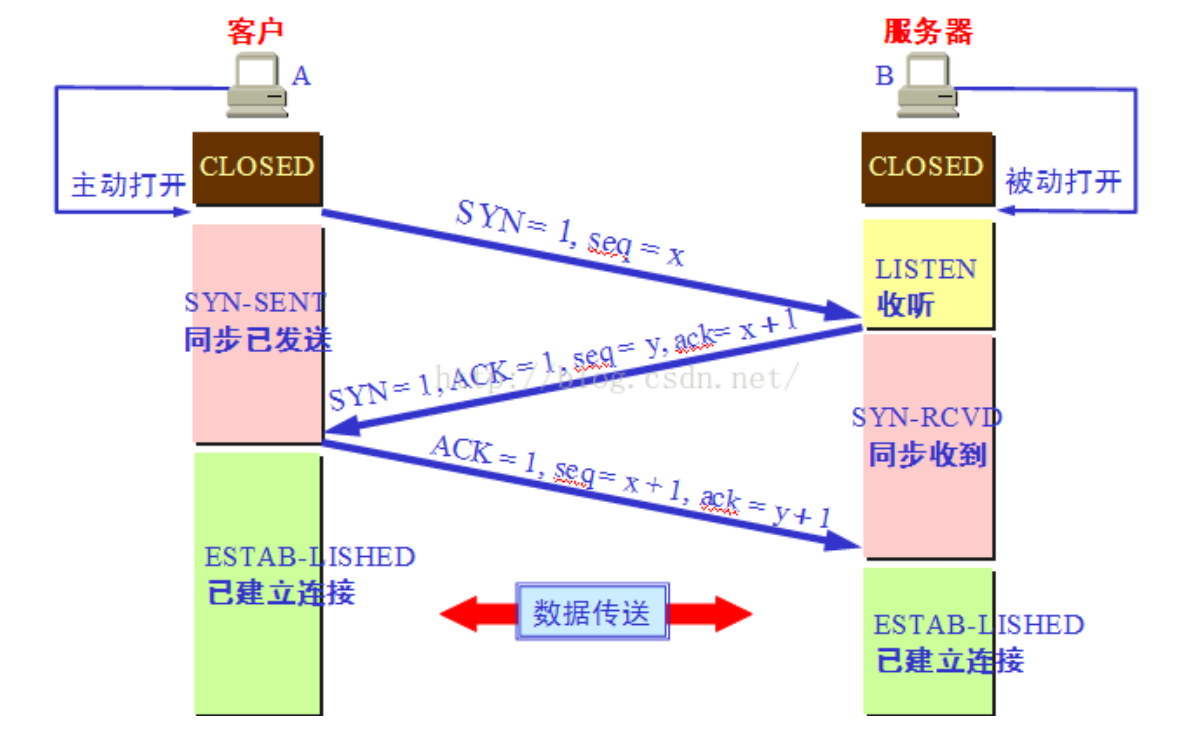
Q: TCP 三次握手/四次挥手
A: TCP 在传输之前会进行三次沟通,一般称为“三次握手”,传完数据断开的时候要进行四次沟通,一般称为“四次挥手”。
三次握手:
第一次握手:主机 A 发送位码为 syn=1,随机产生 seq number=1234567 的数据包到服务器,主机 B由 SYN=1 知道,A 要求建立联机;
第二次握手:主机 B 收到请求后要确认联机信息,向 A 发 送 ack number=( 主 机 A 的seq+1),syn=1,ack=1,随机产生 seq=7654321 的包
第三次握手:主机 A 收到后检查 ack number 是否正确,即第一次发送的 seq number+1,以及位码ack 是否为 1,若正确,主机 A 会再发送 ack number=(主机 B 的 seq+1),ack=1,主机 B 收到后确认eq 值与 ack=1 则连接建立成功。
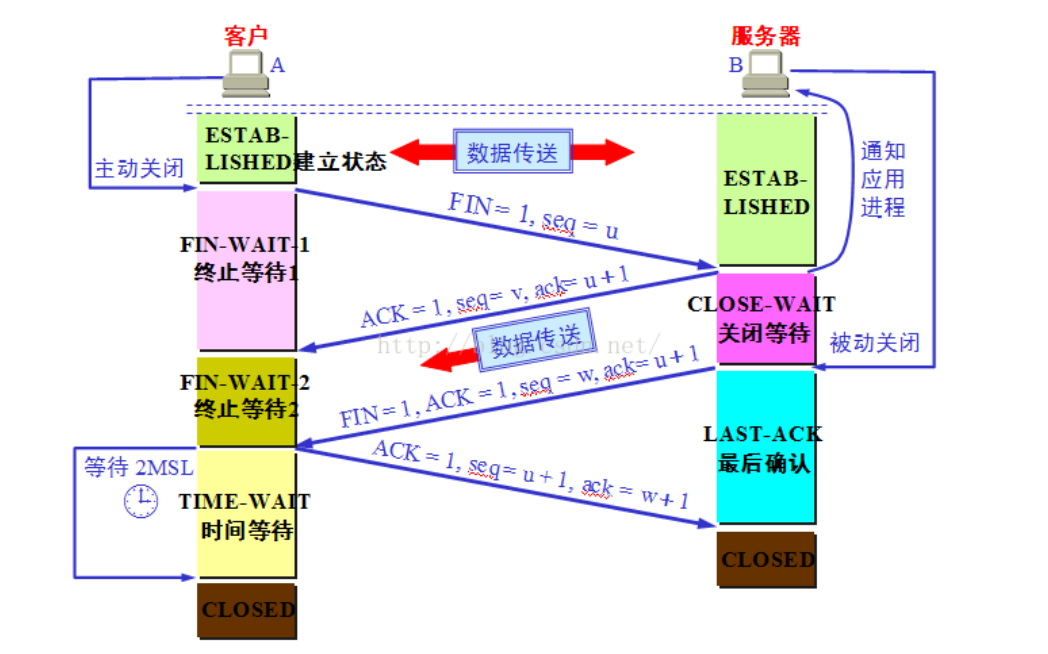
四次挥手:TCP 建立连接要进行三次握手,而断开连接要进行四次。这是由于 TCP 的半关闭造成的。因为 TCP 连接是全双工的(即数据可在两个方向上同时传递)所以进行关闭时每个方向上都要单独进行关闭。这个单方向的关闭就叫半关闭。当一方完成它的数据发送任务,就发送一个 FIN 来向另一方通告将要终止这个方向的连接。
1) 关闭客户端到服务器的连接:首先客户端 A 发送一个 FIN,用来关闭客户到服务器的数据传送,
然后等待服务器的确认。其中终止标志位 FIN=1,序列号 seq=u
2) 服务器收到这个 FIN,它发回一个 ACK,确认号 ack 为收到的序号加 1。
3) 关闭服务器到客户端的连接:也是发送一个 FIN 给客户端。
4) 客户段收到 FIN 后,并发回一个 ACK 报文确认,并将确认序号 seq 设置为收到序号加 1。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
Q: 从浏览器地址栏输入 url 到显示主页的过程
A: 
2,JAVA基础部分
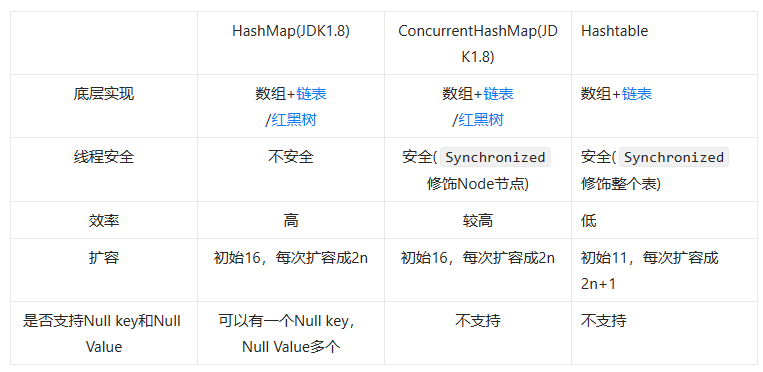
Q: HashMap和Hashtable的区别
A: HashMap是基于哈希表实现的,每一个元素是一个key-value对,其内部通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。
HashMap线程不安全,没有synchronized;HashTable线程安全
Hashtable 中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
HashMap允许key和value为null,HashTable不允许
HashMap继承自AbstractMap类。但二者都实现了Map接口。Hashtable继承自Dictionary类,Dictionary类是一个已经被废弃的类(见其源码中的注释)。父类都被废弃,自然而然也没人用它的子类Hashtable了。
遍历方式: Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。 Enumeration接口的功能和Iterator接口的功能是重复的,主要区别其实就是Iterator可以删除元素,但是Enumration却不能
.HashMap不能保证元素的顺序,而LinkedHashMap可以保持数据的插入顺序,TreeMap可以按照键值进行排序(可自定比较器)
Q: Hashmap 是怎样实现的?为什么要用红黑树,而不用平衡二叉树?为什么在 1.8 中链表大于 8 时会转红黑树?HashMap 是线性安全的嘛?如何保证安全?
A: JDK1.8 Hashmap 的底层数据结构是数组+链表+红黑树
为什么不用二叉树?
红黑树是一种平衡的二叉树,其插入、删除、查找的最坏时间复杂度都为
O(logn),避免了二叉树最坏情况下的 O(n)时间复杂度。
为什么不用平衡二叉树?
平衡二叉树是比红黑树更严格的平衡树,为了保持保持平衡,需要旋转的次数
更多,也就是说平衡二叉树保持平衡的效率更低,所以平衡二叉树插入和删除
的效率比红黑树要低。
Q:深拷贝和浅拷贝区别?
A:浅拷贝:复制了对象的引用地址,两个对象指向同一个内存地址,所以修改其中任意的值,另一个值都会随之变化。
深拷贝: 将对象及值复制过来,两个对象修改其中任意的值另一个值不会改变
Q: 线程生命周期
A:当线程被创建并启动以后,它既不是一启动就进入了执行状态,也不是一直处于执行状态。在线程的生命周期中,它要经过新建(New)、就绪(Runnable)、运行(Running)、阻塞(Blocked)和死亡(Dead)5 种状态。尤其是当线程启动以后,它不可能一直”霸占”着 CPU 独自运行,所以 CPU 需要在多条线程之间切换,于是线程状态也会多次在运行、阻塞之间切换。
yield方法使得线程自动放弃当前分得的CPU时间,等待下一轮CPU时间的分配。相当于说:我执行足够长了,该轮到你执行一会了。
suspend与resume方法对应使用,suspend让线程阻塞,等待resume方法调用,线程才能解除阻塞状态。
Q: 创建多线程的方法
A:
继承Thread类 重写run方法,因为是继承的,不能再继承其他 多个线程不能共享资源
实现Runnable接口
实现Callable接口通过FutureTask包装器来创建Thread线程
与使用Runnable相比, Callable功能更强大些
1 相比run()方法,可以有返回值
2 方法可以抛出异常
3 支持泛型的返回值
使用ExecutorService、Callable、Future实现有返回结果的多线程。
Q:start 与 run 区别
A:
start()方法来启动线程,真正实现了多线程运行。这时无需等待 run 方法体代码执行完毕,可以直接继续执行下面的代码。
通过调用 Thread 类的 start()方法来启动一个线程, 这时此线程是处于就绪状态, 并没有运行。
方法 run()称为线程体,它包含了要执行的这个线程的内容,线程就进入了运行状态,开始运行 run 函数当中的代码。 Run 方法运行结束, 此线程终止。然后 CPU 再调度其它线程。
Q: JAVA锁
乐观锁: 乐观锁是一种乐观思想,即认为读多写少,遇到并发写的可能性低,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,采取在写时先读出当前版本号,然后加锁操作(比较跟上一次的版本号,如果一样则更新),如果失败则要重复读-比较-写的操作。
悲观锁: 悲观锁是就是悲观思想,即认为写多,遇到并发写的可能性高,每次去拿数据的时候都认为别人会修改,所以每次在读写数据的时候都会上锁,这样别人想读写这个数据就会 block 直到拿到锁。java中的悲观锁就是Synchronized,AQS框架下的锁则是先尝试cas乐观锁去获取锁,获取不到,才会转换为悲观锁,如 RetreenLock。
同步锁:当多个线程同时访问同一个数据时,很容易出现问题。为了避免这种情况出现,我们要保证线程同步互斥,就是指并发执行的多个线程,在同一时间内只允许一个线程访问共享数据。 Java 中可以使用 synchronized 关键字来取得一个对象的同步锁。
死锁: 何为死锁,就是多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。
Q:如何在两个线程之间共享数据
A:Java 里面进行多线程通信的主要方式就是共享内存的方式,共享内存主要的关注点有两个:可见性和有序性原子性。Java 内存模型(JMM)解决了可见性和有序性的问题,而锁解决了原子性的问题,理想情况下我们希望做到“同步”和“互斥”。有以下常规实现方法:
- 将数据抽象成一个类,并将数据的操作作为这个类的方法
- Runnable 对象作为一个类的内部类
Q:栈与队列 栈的应用
栈的经典应用:括号匹配、表达式求值和递归函数的递归栈
队列的经典应用:二叉树的层次遍历中
3,Spring 原理部分
Q: Spring Bean 生命周期
A: 简答版,更详细的查看另外的一个比较文件
实例化 Instantiation
属性赋值 Populate
初始化 Initialization
销毁 Destruction
Q: Spring Boot 是怎样启动的?
A:(标准版)
- 运行 SpringApplication.run() 方法。
- 确定应用程序类型。
- 加载所有的初始化器。
- 加载所有的监听器。
- 设置程序运行的主类。
- 开启计时器。
- 将java.awt.headless设置为true。
- 获取并启用监听器
- 设置应用程序参数
- 准备环境变量
- 忽略bean信息
- 打印 banner 信息
- 创建应用程序的上下文
- 实例化异常报告器
- 准备上下文环境
- 刷新上下文
- 刷新上下文后置处理
- 结束计时器
- 发布上下文准备就绪事件
- 执行自定义的run方法
简答版:
- 加载并且启动监听器
- 创建项目运行环境,加载配置
- 初始化 Spring 容器
- 执行 Spring 容器前置处理器
- 刷新 Spring 容器
- 执行 Spring 后置处理器
- 发布事件
- 执行自定义执行器
- 返回容器
Q: Spring MvC执行流程
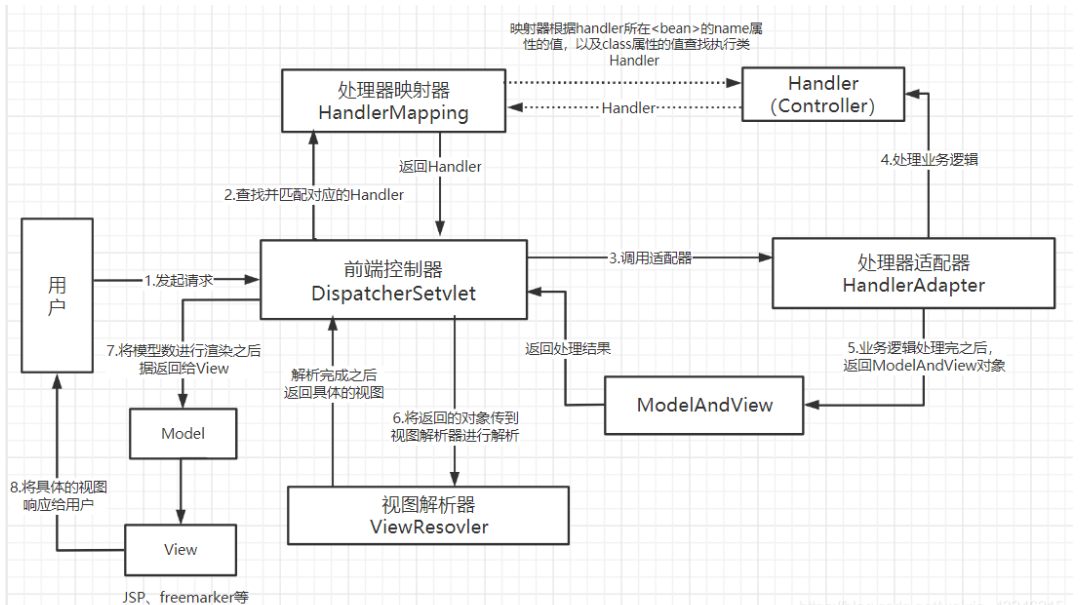
(1)当用户通过浏览器发起一个HTTP请求,请求直接到前端控制器DispatcherServlet;
(2)前端控制器接收到请求以后调用处理器映射器HandlerMapping,处理器映射器根据请求的URL找到具体的Handler,并将它返回给前端控制器;
(3)前端控制器调用处理器适配器HandlerAdapter去适配调用Handler;
(4)处理器适配器会根据Handler去调用真正的处理器去处理请求,并且处理对应的业务逻辑;
(5)当处理器处理完业务之后,会返回一个ModelAndView对象给处理器适配器,HandlerAdapter再将该对象返回给前端控制器;这里的Model是返回的数据对象,View是逻辑上的View。
(6)前端控制器DispatcherServlet将返回的ModelAndView对象传给视图解析器ViewResolver进行解析,解析完成之后就会返回一个具体的视图View给前端控制器。(ViewResolver根据逻辑的View查找具体的View)
(7)前端控制器DispatcherServlet将具体的视图进行渲染,渲染完成之后响应给用户(浏览器显示)。
Q:5 种不同方式的自动装配?
A:Spring 装配包括手动装配和自动装配,手动装配是有基于 xml 装配、构造方法、setter 方法等
自动装配有五种自动装配的方式,可以用来指导 Spring 容器用自动装配方式来进行依赖注入。
- no:默认的方式是不进行自动装配,通过显式设置 ref 属性来进行装配。
- byName:通过参数名 自动装配,Spring 容器在配置文件中发现 bean 的 autowire 属性被设置成 byname,之后容器试图匹配、装配和该 bean 的属性具有相同名字的 bean。
- byType:通过参数类型自动装配,Spring 容器在配置文件中发现 bean 的 autowire 属性被
设置成 byType,之后容器试图匹配、装配和该 bean 的属性具有相同类型的 bean。如果有多
个 bean 符合条件,则抛出错误。 - constructor:这个方式类似于 byType, 但是要提供给构造器参数,如果没有确定的带参数
的构造器参数类型,将会抛出异常。 - autodetect:首先尝试使用 constructor 来自动装配,如果无法工作,则使用 byType 方式
Q:Spring MVC和Spring Boot有什么区别?
A:
Spring mvc 是web层的框架,通过Controller提供Http接口服务。
Spring Boot 是一种快速搭建的脚手架,通过依赖各种Starter,省略了Spring特别多而繁琐的xml配置。
两者作为Spring生态中的组件,产生时间不同,spring mvc很早就诞生,例如之前最主流的企业开发框架ssm,就用到了Spring mvc。Spring Boot作为后起之秀,通过“约定大于配置”来减少许多配置,大大的提高了生产力。
Q:JAVA过滤器(Filter)与拦截器(Interceptor)区别及关系
1、过滤器是基于函数回调,而拦截器是基于java的反射机制;
2、过滤器是servlet规范规定的,只能用于web程序中,而拦截器是在spring容器中,它不依赖servlet容器
3、过滤器可以拦截几乎所有的请求(包含对静态资源的请求),而拦截器只拦截action请求(不拦截静态资源请求)
4、过滤器不能访问action上下文及值栈里的对象,而拦截器都是可以的。
5、拦截器可以获取spring容器里的对象,而过滤器是不行的
6、拦截器在action的生命周期内是可以多次调用,而过滤器只在容器初始化时被调用一次。
7、拦截器是被包裹在过滤器之中。
Q: Spring 中的事务
- spring事务的实现方式
spring框架提供了两种事务实现方式:编程式事务、声明式事务
编程式事务:在代码中进行事务控制。优点:精度高。缺点:代码耦合度高
声明式事务:通过@Transactional注解实现事务控制 - spring事务的底层原理
事务的操作本来应该由数据库进行控制,但是为了方便用户进行业务逻辑的控制,spring对事务功能进行了扩展实现。一般我们很少使用编程式事务,更多的是使用@Transactional注解实现。当使用了@Transactional注解后事务的自动功能就会关闭,由spring帮助实现事务的控制。
Spring的事务管理是通过AOP代理实现的,对被代理对象的每个方法进行拦截,在方法执行前启动事务,在方法执行完成后根据是否有异常及异常的类型进行提交或回滚。
Spring AOP动态代理机制:
Spring在运行期间会为目标对象生成一个代理对象,并在代理对象中实现对目标对象的增强。
SpringAOP通过两种动态代理机制,实现对目标对象执行横向植入的。
代理技术 描述
JDK 动态代理 Spring AOP 默认的动态代理方式,若目标对象实现了若干接口,Spring 使用 JDK 的 java.lang.reflect.Proxy 类进行代理。
CGLIB 动态代理 若目标对象没有实现任何接口,Spring 则使用 CGLIB 库生成目标对象的子类,以实现对目标对象的代理。
Q:
4,MySQL部分
Q: SQL语句执行过程(顺序)
FROM子句组装来自不同数据源的数据;WHERE子句基于指定的条件对记录行进行筛选;GROUP BY子句将数据划分为多个分组;使用聚集函数进行计算;
使用
HAVING子句筛选分组;计算所有的表达式;
SELECT的字段;使用
ORDER BY对结果集进行排序。
Q:索引哪些情况会失效
A:
. 查询条件包含or,可能导致索引失效
. 如何字段类型是字符串,where时一定用引号括起来,否则索引失效
. like通配符可能导致索引失效。
. 联合索引,查询时的条件列不是联合索引中的第一个列,索引失效。
. 在索引列上使用mysql的内置函数,索引失效。
. 对索引列运算(如,+、-、*、/),索引失效。
. 索引字段上使用(!= 或者 < >,not in)时,可能会导致索引失效。
. 索引字段上使用is null, is not null,可能导致索引失效。
. 左连接查询或者右连接查询查询关联的字段编码格式不一样,可能导致索引失效。
. mysql估计使用全表扫描要比使用索引快,则不使用索引。
Q:数据库索引的原理,为什么要用 B+树,为什么不用二叉树
A:从几个维度去看这个问题,查询是否够快,效率是否稳定,存储数据多少,
以及查找磁盘次数,为什么不是二叉树:
为什么不是一般二叉树?
如果二叉树特殊化为一个链表,相当于全表扫描。平衡二叉树相比于二叉查找
树来说,查找效率更稳定,总体的查找速度也更快。
为什么不是平衡二叉树呢?
但是平衡二叉树可是每个节点只存储一个键值和数据的,如果
是B树,可以存储更多的节点数据,树的高度也会降低,因此读取磁盘的次数
就降下来啦,查询效率就快啦。
那为什么不是B树而是B+树呢?
B+树非叶子节点上是不存储数据的,仅存储键值,而B树节点中不仅存储
键值,也会存储数据。innodb中页的默认大小是16KB,如果不存储数据,那
么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就
会更矮更胖,如此一来我们查找数据进行磁盘的IO次数有会再次减少,数据查
询的效率也会更快
聚集索引与非聚集索引的区别?
A:
- 一个表中只能拥有一个聚集索引,而非聚集索引一个表可以存在多个。
- 聚集索引,索引中键值的逻辑顺序决定了表中相应行的物理顺序;非聚集索引,索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同。
- 索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
- 聚集索引:物理存储按照索引排序;非聚集索引:物理存储不按照索引排序;
Q:SQL优化的一般步骤是什么
A:
- show status 命令了解各种sql的执行频率
- 通过慢查询日志定位那些执行效率较低的sql语句
- explain 分析低效 sql 的执行计划(这点非常重要,日常开发中用它分析Sql,会大大降低Sql导致的线上事故)

